Curso rapido de Machine Learning: Parte 1
31 Dec 2016Daniel Geng y Shannon Shih de la Universidad de Berkeley publicaron un crash course sobre Machine Learning bastante interesante y con una curva de aprendizaje muy bien manejada. Me tomo la libertad de traducir y publicar los artículos, sin buscar una precisión excesiva, simplemente que se entienda tan bien en español como en ingles. Que los disfruten!
Introducción, Regresión/Clasificación, Cost Functions, y Método del Gradiente
Machine learning (ML) ha recibido mucha atención recientemente, y no sin una buena razón. Ya ha revolucionado distintos campos, desde el reconocimiento de imágenes hasta la salud y el transporte. Sin embargo, una explicación típica para el aprendizaje de máquina suena así:
“Se dice de un programa de computadora que aprende de la experiencia E con respecto a alguna clase de tareas T y la medida de desempeño P si su desempeño en tareas en T, medido por P, mejora con la experiencia E.”
No muy simpático, ¿verdad? Este post, el primero de una serie de tutoriales, tiene como objetivo hacer que Machine Learning sea accesible a cualquier persona dispuesta a aprender. Lo hemos diseñado para darle una sólida comprensión de cómo funcionan los algoritmos de ML, así como proporcionarle el conocimiento para aprovecharlo en sus proyectos.
Entonces… qué es Machine Learning?
En su esencia ML no es un concepto difícil de comprender. De hecho, la gran mayoría de los algoritmos de ML se ocupan de una simple tarea: dibujar líneas, mas específicamente de dibujar líneas a través de datos. Qué significa eso? Veamos un ejemplo sencillo.
Clasificación
Digamos que usted es una computadora con una colección de imágenes de manzanas y naranjas. De cada imagen se puede inferir el color y el tamaño de una fruta, y desea clasificar las imágenes como una imagen de una manzana o una naranja. El primer paso en muchos algoritmos es obtener datos de entrenamiento. En nuestro ejemplo, esto significa obtener un gran número de imágenes de frutas cada una etiquetada como manzana o naranja. A partir de estas imágenes, podemos extraer el color y la información del tamaño y luego ver cómo se correlacionan con ser una manzana o una naranja. Por ejemplo, graficar nuestros datos de entrenamiento etiquetados puede parecer algo así:

Las x rojas se denominan manzanas y las x naranjas se etiquetan como naranjas. Probablemente notará que hay un patrón en los datos. Las manzanas parecen reunirse en el lado izquierdo del gráfico porque son en su mayoría de color rojo, y las naranjas parecen congregarse en el lado derecho porque son en su mayoría de color naranja. Queremos que nuestro algoritmo aprenda estos tipos de patrones.
Para este problema en particular, nuestro objetivo es crear un algoritmo que dibuje una línea entre los dos grupos etiquetados, se la denomina límite de decisión (decision boundary). El límite de decisión más simple para nuestros datos podría ser algo como esto:

Sólo una línea recta entre las manzanas y las naranjas. Sin embargo, los algoritmos mucho más complejos pueden terminar dibujando límites de decisión mucho más complicados:

Nuestra suposición es que la línea que hemos dibujado, para distinguir entre las imágenes de manzanas y naranjas de nuestros datos de entrenamiento, será capaz de diferenciar una manzana de una naranja en cualquier imagen. En otras palabras, al dar a nuestro algoritmo ejemplos de manzanas y naranjas para aprender, puede generalizar su experiencia a las imágenes de manzanas y naranjas que nunca ha encontrado antes. Por ejemplo, si nos dieron una imagen de un fruto, representado por la X azul, podríamos clasificarlo como una naranja basado en el límite de decisión que dibujamos:

Este es el poder del aprendizaje automático. Tomamos algunos datos de entrenamiento, ejecutamos un algoritmo (programa) de Machine Learning que dibuja un límite de decisión sobre los datos, y luego extrapolar lo que hemos aprendido a piezas completamente nuevas de datos.
Por supuesto, distinguir entre manzanas y naranjas es una tarea bastante mundana. Sin embargo, podemos aplicar esta estrategia a problemas mucho más emocionantes, como clasificar los tumores como malignos o benignos, marcar los correos electrónicos como spam o no como spam, o analizar las huellas dactilares de los sistemas de seguridad. Este tipo de aprendizaje de ML-líneas de dibujo para separar los datos es sólo un subcampo, llamado clasificación. Otro subcampo, llamado regresión, trata de dibujar líneas que describen datos.
Regresión
Digamos que tenemos algunos datos de entrenamiento etiquetados. En particular, digamos que tenemos el precio de varias casas en relación a su superficie. Si visualizamos la información como un gráfico se ve así:

Cada uno de las X representa una casa con determinado precio y metros cuadrados. Observe que aunque hay alguna variación en los datos (en otras palabras, cada punto de datos es un poco disperso, pero también que hay un patrón: a medida que las casas se hacen más grandes, también se vuelven más caras. Queremos que nuestro algoritmo encuentre y utilice este patrón para predecir los precios de la vivienda basados en el tamaño de la casa.
Simplemente mirando los datos de entrenamiento podemos ver que hay una franja diagonal en la gráfica en la que la mayoría de las casas parecen aterrizar. Podemos generalizar esta idea y decir que todas las casas tendrán una alta probabilidad de estar en el conjunto diagonal de puntos de datos. Por ejemplo, hay una probabilidad bastante alta de que una casa esté en la X verde en el gráfico de abajo y una probabilidad bastante baja de que una casa esté en la X roja en el gráfico de abajo.

Ahora podemos generalizar aún más y preguntar, para una determinada cantidad de metros cuadrados, ¿Cuánto vale la pena pagar por una casa? Por supuesto, sería muy difícil obtener una respuesta exacta. Sin embargo, una respuesta aproximada es mucho más fácil de conseguir. Para ello, trazamos una línea a través del conjunto de datos, lo más cerca posible de cada punto de datos. Esta línea, llamada un predictor, predice el precio de una casa según su tamaño. Para cualquier punto en el predictor, existe una alta probabilidad de que una casa de esa superficie tenga ese precio. En cierto sentido, podemos decir que el predictor representa una “media” de los precios de la vivienda para un metraje dado.

El predictor no necesariamente tiene que ser lineal. Puede ser cualquier tipo de función, o modelo, que se pueda imaginar: funciones cuadráticas, sinusoidales e incluso arbitrarias funcionarán. Sin embargo, el uso del modelo más complejo para un predictor no siempre funcionará; Diferentes funciones encuadran mejor para diferentes problemas, y es el programador el que debe averiguar qué tipo de modelo a utilizar.
Mirando nuevamente nuestro modelo de precio de la vivienda, podríamos preguntarnos: ¿Por qué limitarnos a una sola variable de entrada? Podemos considerar tantos tipos de información como queramos, tales como el costo de vida en la ciudad, estado de la vivienda, material de construcción, y así sucesivamente. Por ejemplo, podemos calcular el precio en función del costo de vida en la ubicación de la casa y sus metros cuadrados en un solo gráfico como éste, donde el eje vertical dibuja el precio y los dos ejes horizontales representan la superficie cuadrada y el costo de vida:
En este caso podemos ajustar un predictor a los datos. Pero en lugar de dibujar una línea a través de los datos que tenemos que dibujar un plano a través de los datos, porque la función que mejor predice el precio de la vivienda es una función de dos variables (ubicación y tamaño).
Así que hemos visto ejemplos de una y dos variables de entrada, pero muchas aplicaciones de ML toman en cuenta cientos e incluso miles de variables. Aunque los seres humanos lamentablemente somos incapaces de visualizar algo superior a tres dimensiones, los mismos principios que acabamos de aprender se aplicarán a esos sistemas.
El predictor
Como mencionamos anteriormente, hay muchos tipos diferentes de predictores. En nuestro ejemplo con los precios de la vivienda, utilizamos un modelo lineal para aproximar nuestros datos. La forma matemática de un predictor lineal se parece a esto:
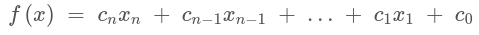
Cada x representa una característica de entrada diferente, como la cantidad de metros cuadrados o el costo de vida, y cada c se llama parámetro o peso. Cuanto mayor es un peso particular, más el modelo considera su característica correspondiente. Por ejemplo, el metraje cuadrado es un buen predictor de los precios de la vivienda, por lo que nuestro algoritmo debe dar a la metraje una gran cantidad de consideración al aumentar el coeficiente asociado. En contraste, si nuestros datos incluyen el número de tomas de corriente en la casa, nuestro algoritmo probablemente le dará un peso relativamente bajo porque no tiene mucho que ver con el precio de una casa.
En nuestro ejemplo de predecir los precios de la vivienda basados en los metros cuadrados, ya que sólo estamos considerando una variable, nuestro modelo sólo necesita una característica de entrada, o sólo una x:
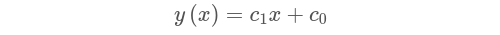
Probablemente la ecuación es más reconocible en esta forma:
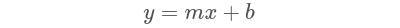
Y(x) es nuestra salida, o en este caso el precio de una casa, y X es nuestra característica, o en este caso el tamaño de la casa. C0 es la intersección y, para dar cuenta del precio base de la casa. Ahora la pregunta es: ¿Cómo el algoritmo de Machine Learning elige c2 y c1 para que la línea prediga mejor los precios de la vivienda?
Vale la pena señalar que los coeficientes pueden ser encontrados directamente y muy eficientemente a través de una relación matricial llamada la ecuación normal. Sin embargo, dado que este método se vuelve poco práctico cuando se trabaja con cientos o miles de variables, usaremos el método que usan los algoritmos de Machine Learning.
Funciones de costo
La clave para determinar qué parámetros elegir para aproximar mejor los datos es encontrar una manera de caracterizar cuan “equivocado” es nuestro predictor. Lo hacemos utilizando una función de costo (o una función de pérdida). Una función de costo toma una línea y un conjunto de datos y devuelve un valor denominado costo. Si la línea se aproxima a los datos el costo será bajo, y si la línea se aleja de los datos el costo será alto.
El mejor predictor minimizará la salida de la función de costo, o en otras palabras, minimizará el costo. Para visualizar esto, veamos las tres funciones de predicción a continuación:
. Podemos visualizar el error usando el siguiente gráfico, donde cada una de las barras es diferente (xi-yi).

Así que para un único punto de datos (Xi, yi), donde xi es el metraje cuadrado de la casa y yi es el precio de la casa, y un predictor y (x) el error cuadrado es:
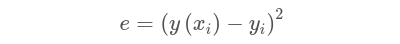
Lo bueno del cuadrado del error es que todo es positivo. De esta manera podemos minimizar el error al cuadrado. Ahora tomamos la media, o el promedio, sobre todos los puntos de datos para obtener el error cuadrático medio:
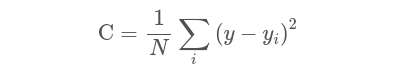
Aquí, hemos resumido todos los errores al cuadrado, y dividido por N, que es el número de puntos de datos que tenemos, que es sólo la media de los errores al cuadrado. Por tanto, el error cuadrático medio.
Método del Gradiente
Cuando graficamos la función de costo (con sólo dos variables) se verá algo como esto:
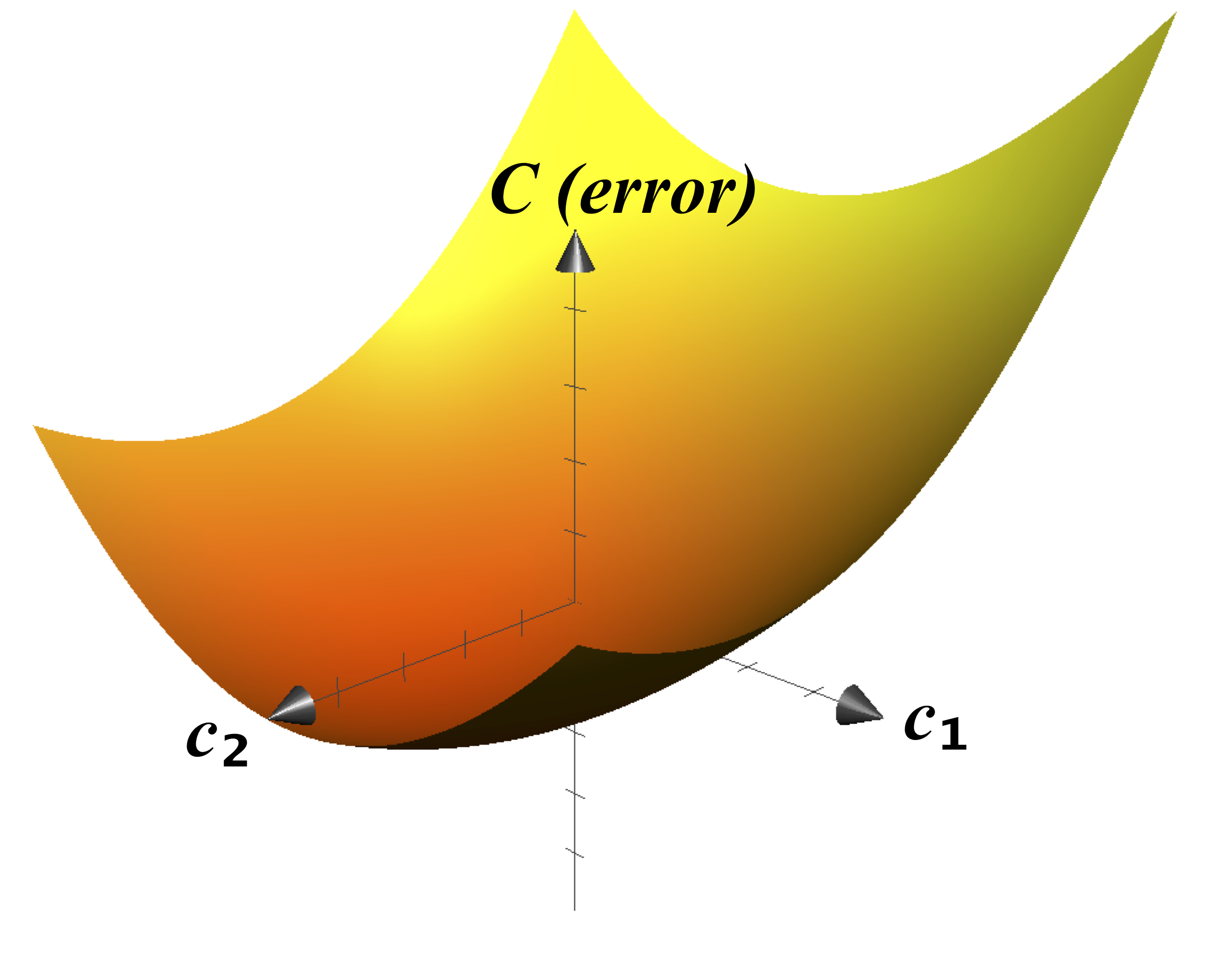
Ahora es bastante evidente donde el mínimo de esta función de costo. Sin embargo recuerde que sólo tenemos una función de metros cuadrados. En realidad, casi todas las aplicaciones para algoritmos modernos de aprendizaje de máquina toman mucho más que una característica. En algunos casos, se utilizan hasta decenas de millones de parámetros, ¡diviértase intentando imaginar un espacio de diez millones de dimensiones!
Por lo tanto, cuando tenemos un número de dimensiones muy alto y queremos encontrar el costo mínimo, vamos a utilizar un algoritmo llamado descenso gradiente o método del gradiente. Como veremos a continuación, el descenso gradiente tiene una explicación muy intuitiva en dos dimensiones, pero el algoritmo también se generaliza fácilmente a cualquier número de dimensiones.
Para empezar, imagine rodar una pelota a lo largo del gráfico de la función de costos. A medida que la bola rueda, siempre seguirá la ruta más empinada, eventualmente llegará a descansar en la parte inferior. En pocas palabras, eso es lo que es el descenso gradiente. Elegimos cualquier punto de la gráfica, encontramos la dirección que tiene la pendiente más empinada, nos movemos un poco en esa dirección y repetimos. Eventualmente, necesariamente tenemos que alcanzar un mínimo de la función de costo. Y porque ese punto es el mínimo de la función de coste, también lo son los parámetros que usaremos para dibujar nuestra línea.
Entonces, ¿Qué acabo de aprender?
Así que después de leer todo esto esperamos qye Machine Learning esté empezando a tener más sentido para usted. Y espero que no parezca tan complicado como pensó una vez que era. Sólo recuerde que Machine Learning es literalmente sólo líneas a través de datos de entrenamiento. Decidimos que propósito tiene la linea, como un límite de decisión en un algoritmo de clasificación, o un predictor que modela el comportamiento del mundo real. Y estas líneas a su vez sólo vienen de encontrar el mínimo de una función de coste utilizando el descenso gradiente.
Dicho de otra manera, realmente ML es sólo el reconocimiento de patrones. Los algoritmos ML aprenden patrones dibujando líneas a través de datos de entrenamiento, y luego generalizan los patrones que ve a nuevos datos. Pero eso plantea la pregunta: ¿el aprendizaje automático realmente “aprende”? Bueno, ¿quién puede decir que el aprendizaje no es sólo reconocimiento de patrones?